Just another Binusian blog site
hiddenarmy
This user hasn't shared any profile information
Posts by hiddenarmy
T0553 – Sistem Multimedia Laporan Project UAS “Nightmare”
012 years
T0553 – SISTEM MULTIMEDIA
LAPORAN PEMBUATAN PROJECT APLIKASI
“Nightmare”
04PLT
Kelompok 3:
David Febryanto (1601222070)
Edward Ivan Fadli (1601218874)
Sudiarto Winata (1601223786)
Kenzu Pangestu (1601224864)
Wira Adi Putra(1601223451)
1. Deskripsi Aplikasi
Aplikasi yang kami buat pada kali ini memiliki keterkaitan dengan project video yang telah kami buat sebelumnya, yaitu bertemakan horror. Nama aplikasi yang kami buat saat ini adalah Nightmare Aplikasi ini berawal dari tampilan welcome yang memberikan suasana yang menyeramkan, sesuai dengan temanya agar dapat memberikan suasana horror bagi para user.
Setelah user masuk atau meng-klik enter, user dapat melihat trailer, detail-detail dan rating dari lima film horror terbaik secara terpisah. Selain itu, user juga dapat melihat review dari kelima film tersebut secara keseluruhan melalui pilihan “Our review”, yang kemudian akan menampilkan video yang merupakan project video yang telah kami buat sebelumnya. Terakhir, “Click to subscribe” dapat digunakan juga untuk berlangganan secara langsung pada aplikasi Nightmare untuk mendapatkan informasi terbaru ke depannya.
2. Pembuatan Aplikasi

Aplikasi Multimedia yang kami buat ini menggunakan Adobe Flash CS3 Professional version 9.0 sebagai toolnya.
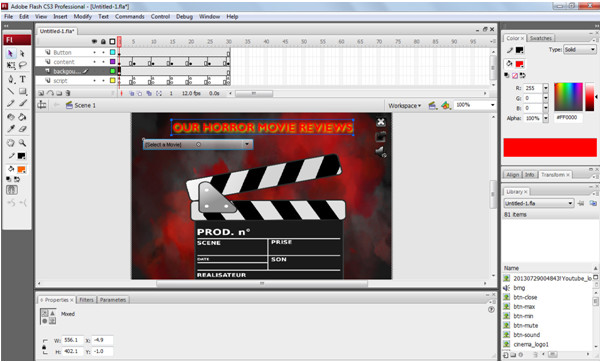
Gambar diatas adalah saat kami melakukan pengaturan layer dan frame dalam aplikasi yang kami buat.
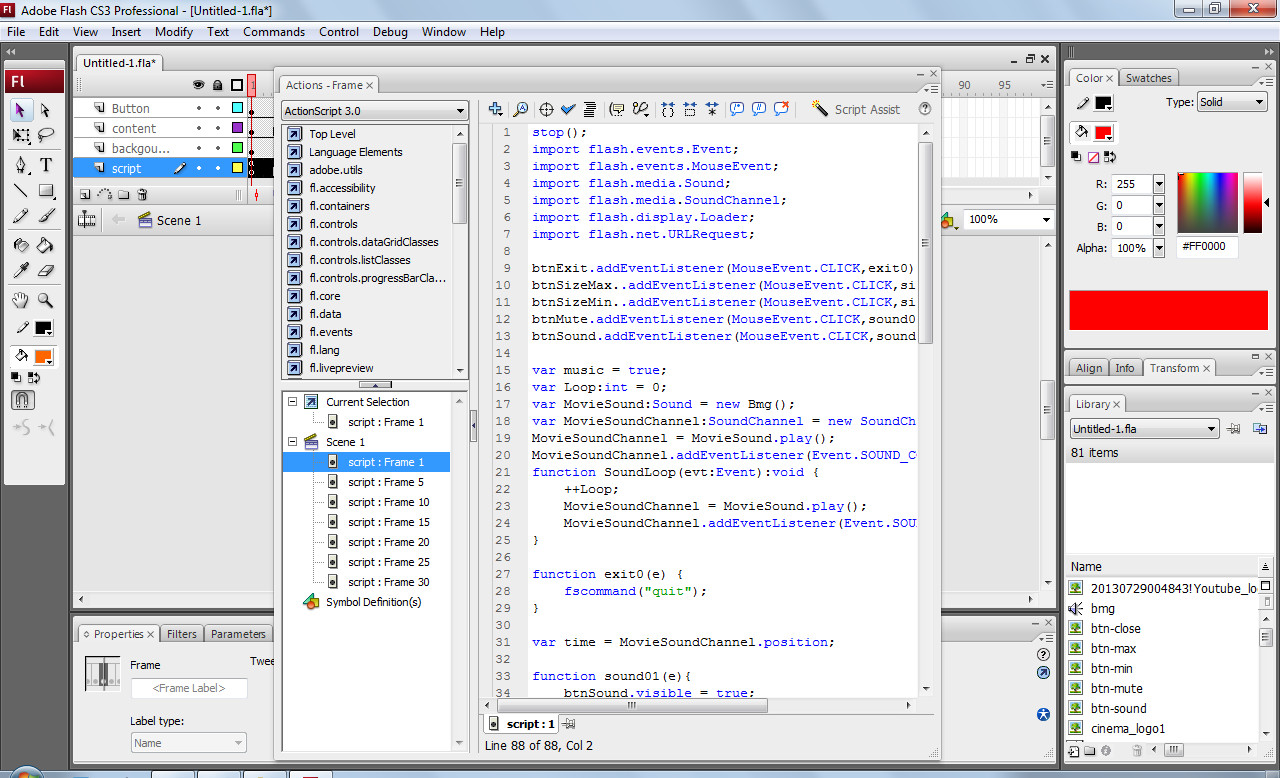
Pada gambar di atas, kami menggunakan script pada pembuatan aplikasi ini supaya bisa menjalankan fungsi pada button serta pengaturan pada frame.
3. Screenshot Aplikasi

[1] Gambar diatas adalah bagian awal dari aplikasi Nightmare. Ketika user melakukan klik pada logo Nightmare, maka user akan masuk ke bagian credits. Logo Nightmare tidak hanya ada di bagian ini, namun ada di bagian lain dan akan memberikan akses yang sama juga (ke bagian credits). Ketika pintu di-klik, maka user akan masuk ke bagian selanjutnya.

[2] Gambar diatas adalah bagian credits ketika logo Nightmare di-klik. Pada bagian Credits ini terdapat nama-nama anggota kelompok pembuat aplikasi Nightmare ini. User dapat meng-klik Back to home apabila ingin kembali lagi ke halaman utama.
Note : Logo Nightmare pada tampilan diatas ini tidak memberikan akses apa-apa.

[3] Gambar diatas ini adalah bagian Home pada aplikasi Nightmare. Pada bagian Home ini, terdapat tombol “Click here to subscribe” dan “Select a Movie” serta terdapat logo Nightmare untuk menampilkan credits.
Click here to subscribe : Akses ke form subscribe. User akan diminta untuk mengisi nama dan email agar dapat berlangganan dengan Nightmare.
Select a Movie : User memilih film sesuai dengan kemauan sehingga dapat melihat trailer dan detailnya. Terdapat “Our Review” dalam pilihan tersebut yang berarti itu adalah video kompilasi dari 5 film horror yang kami sediakan dan dibuat dalam bentuk review singkat.
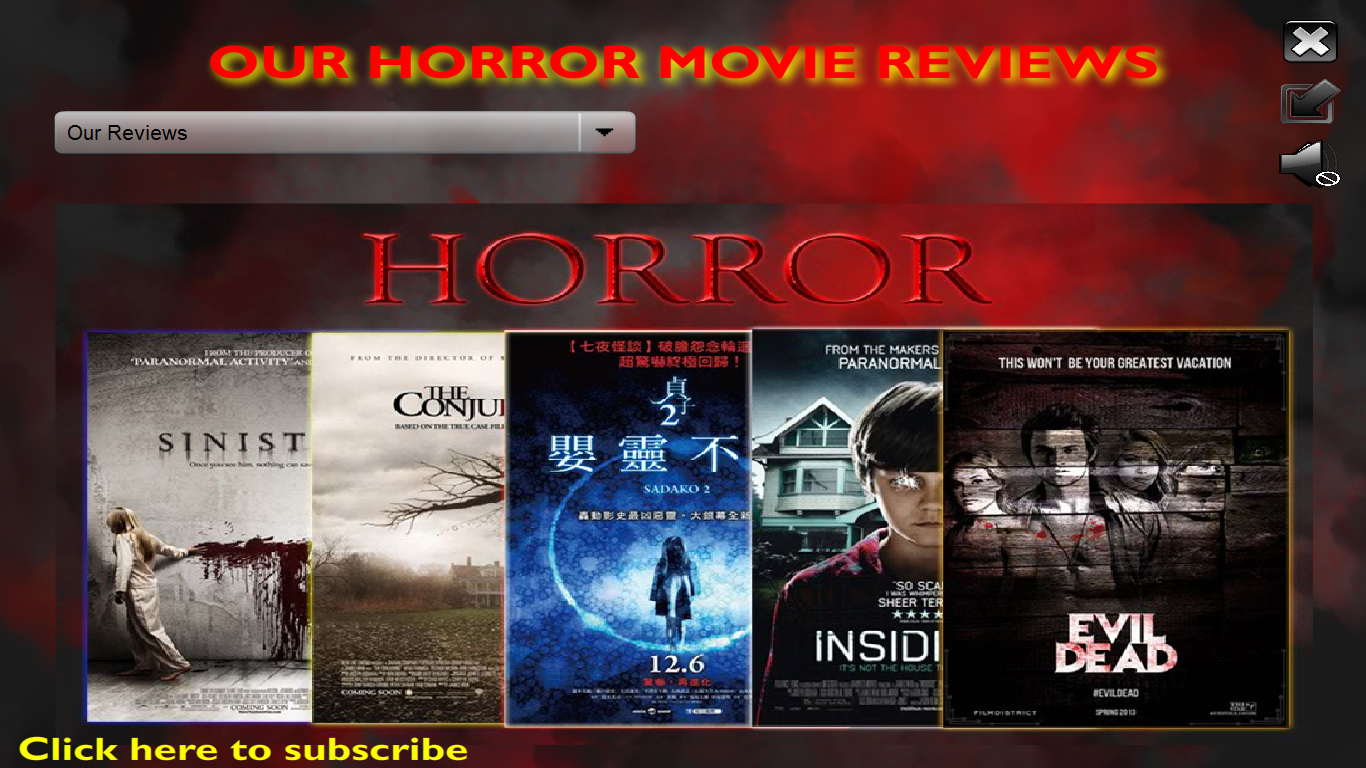
[4] Gambar diatas adalah tampilan apabila user meng-klik Our Reviews saat memilih film. Kelima film horror akan ditampilkan dan user dapat melihat trailer secara keseluruhan beserta review singkat dari kami mengenai kelima film tersebut secara personal.

[5] Gambar diatas merupakan salah satu bagian pada saat salah satu film di-klik. Saat film di-klik maka akan muncul cover film, judul, detail, rating, logo Nightmare, dan tombol subscribe.
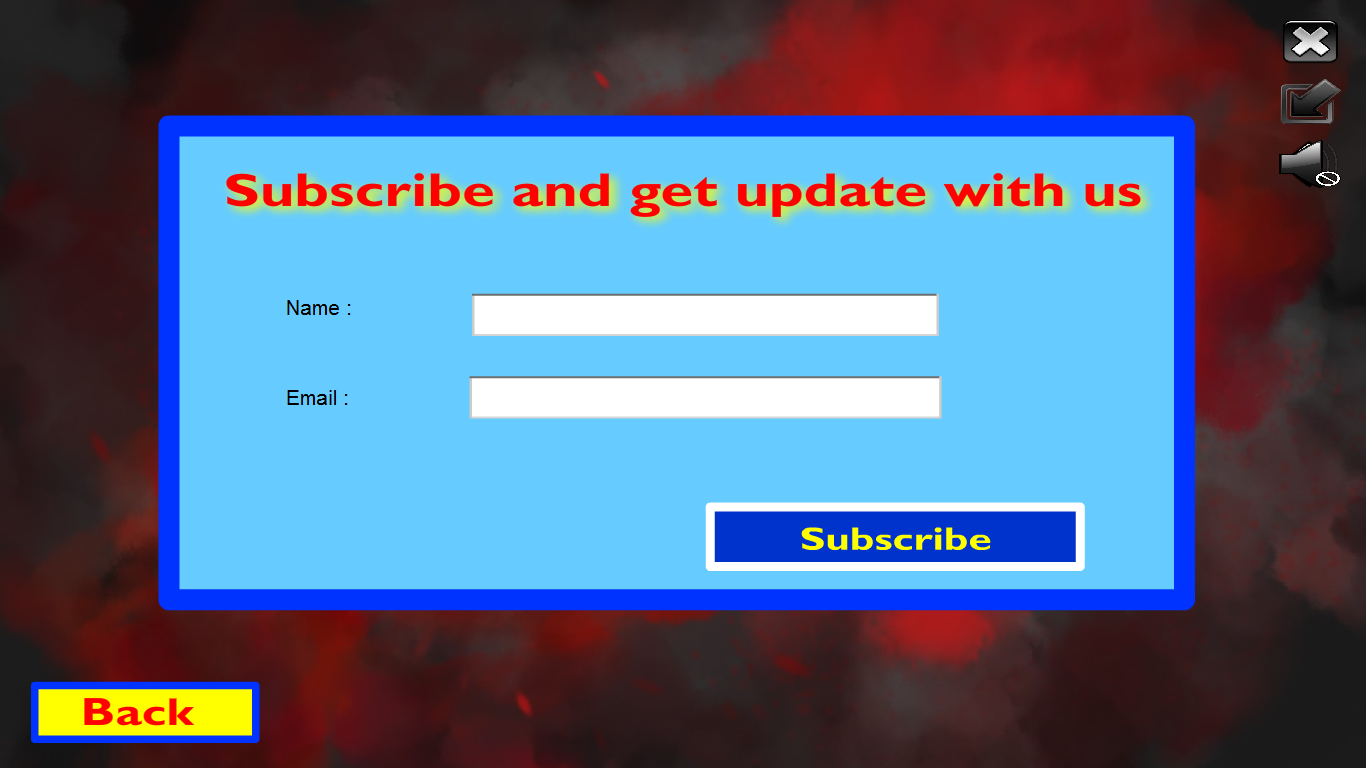
[6] Gambar diatas merupakan bagian yang muncul ketika user melakukan klik pada button “Click here to subscribe”. Pada bagian ini terdapat form yang berisi nama dan email. Kami memberikan validasi pada nama untuk tidak boleh menginput angka dan kami melakukan validasi pada email juga untuk diinput dengan format yang benar / sesuai dengan email. Setelah itu, anda dapat melakukan subscribe dengan meng-klik Subscribe.

[7] Setelah melakukan klik pada button “Subscribe” maka akan muncul tulisan “Thanks for subcribe” dan anda bisa melakukan klik pada button Back to home. Dengan demikian anda telah berlangganan dengan Nightmare.
![]()
[8] Logo Aplikasi kami, Nightmare
Download aplikasi kami di sini :
Nightmare app
Tugas T0264 – Intelegensia Semu GSLC 3 (31 Mei 2014)
012 years
Rangkuman untuk Pertemuan 22 Natural Language Processing
1. Text Classification / Text Categorization
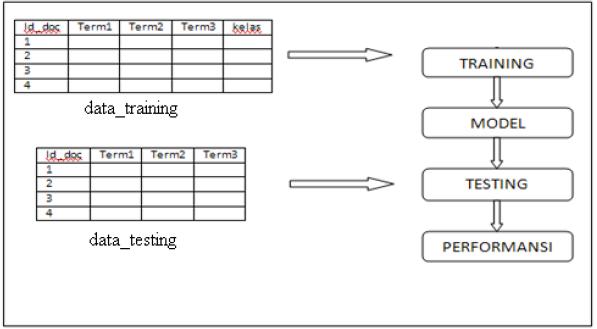
Salah satu contoh pemanfaatan teks mining adalah text categorization yaitu proses pengelompokan dokumen, yang dalam tugas akhir ini adalah konten web page, ke dalam beberapa kelas yang telah ditentukan. Jika tidak ada overlap antar kelas, yaitu setiap dokumen hanya dikelompokan kedalam satu kelas maka text categorization ini disebut single label text categorization . Text categorization bertujuan untuk menemukan model dalam mengkategorisasikan teks natural language. Model tersebut akan digunakan untuk menentukan kelas dari suatu dokumen.
Beberapa metode text categorization yang sering dipakai antara lain : k- Nearest Neighbor, Naïve Bayes, Support Vektor Machine, Decision Tree, Neural Networks, Boosting. Dalam pengaplikasian text categorization terdapat beberapa tahap, yaitu : preprocessing, training phase dan testing phase.
Preprocessing
Tahap pertama dalam text categorization adalah dokumen preprocessing adalah :
1. Ekstrasi Term
Ekstrasi term dilakukan untuk menentukan kumpulan term yang mendeskripsikan dokumen. Kumpulan dokumen di parsing untuk menghasilkan daftar term yang ada pada seluruh dokumen. Daftar term yang dihasilkan disaring dengan membuang tanda baca, angka, simbol dan stopwords. Dalam tugas akhir ini akan dibahas juga mengenai pengaruh stopwords removal terhadap hasil klasifikasi. Berikut ini merupakan penjelasan singkat mengenai stopwords.
Kebanyakan bahasa resmi di berbagai negara memiliki kata fungsi dan kata sambung seperti artikel dan preposisi yang hampir selalu muncul pada dokumen teks. Biasanya kata-kata ini tidak memiliki arti yang lebih di dalam memenuhi kebutuhan seorang searcher di dalam mencari informasi. Kata-kata tersebut (misalnya a, an, dan on pada bahasa Inggris) disebut sebagai Stopwords.
Sebuah sistem Text Retrieval biasanya disertai dengan sebuah Stoplist. Stoplist berisi sekumpulan kata yang ‘tidak relevan’, namun sering sekali muncul dalam sebuah dokumen. Dengan kata lain Stoplist berisi sekumpulan Stopwords.
Stopwords removal adalah sebuah proses untuk menghilangkan kata yang ‘tidak relevan’ pada hasil parsing sebuah dokumen teks dengan cara membandingkannya dengan Stoplist yang ada.
2. Seleksi Term
Jumlah term yang dihasilkan pada feature ekstrasi dapat menjadi suatu data yang berdimensi cukup besar. Karena dimensi dari ruang feature merupakan bag-of-words hasil pemisahan kata dari dokumennya. Untuk itu perlu dilakukan feature selection untuk mengurangi jumlah dimensi.
3. Representasi Dokumen
Supaya teks natural language dapat digunakan sebagai inputan untuk metode klasifikasi maka teks natural language diubah kedalam representasi vektor. Dokumen direpresentasikan sebagai vektor dari bobot term, dimana setiap term menggambarkan informasi khusus tentang suatu dokumen. Pembobotan dilakukan dengan melakukan perhitungan TFIDF. Term beserta bobotnya kemudian disusun dalam bentuk matrik.
Training Phase
Tahap kedua dari text categorization adalah training. Pada tahap ini system akan membangun model yang berfungsi untuk menentukan kelas dari dokumen yang belum diketahui kelasnya. Tahap ini menggunakan data yang telah diketahui kelasnya (data training) yang kemudian akan dibentuk model yang direpresantasikan melalui data statistik berupa mean dan standar deviasi masing-masing term pada setiap kelas.
Testing Phase
Tahap terakhir adalah tahap pengujian yang akan memberikan kelas pada data testing dengan menggunakan model yang telah dibangun pada tahap training. Tujuan dilakukan testing adalah untuk mengetahui performansi dari model yang telah dibentuk. Dengan beberapa parameter pengukuran yaitu akurasi, precision, recall, dan f-measure.
Pembobotan
Vector space model merepresentasikan dokumen dengan term yang memiliki bobot. Bobot tersebut menyatakan kepentingan/kontribusi term terhadap suatu dokumen dan kumpulan dokumen. Kepentingan suatu kata dalam dokumen dapat dilihat dari frekuensi kemunculannya terhadap dokumen. Biasanya term yang berbeda memiliki frekuensi yang berbeda. Dibawah ini terdapat beberapa metode pembobotan :
1. Term Frequency
Term frequency merupakan metode yang paling sederhana dalam membobotkan setiap term. Setiap term diasumsikan memiliki kepentingan yang proporsional terhadap jumlah kemunculan term pada dokumen. Bobot dari term t pada dokumen d yaitu :
TF(d,t) = f (d, t)
Dimana f(d,t) adalah frekuensi kemunculan term t pada dokumen d
2. Inverse Document Frequency (IDF)
Bila term frequency memperhatiakan kemunculan term didalam dokumen, maka IDF memperhatikan kemunculan term pada kumpulan dokumen. Latar belakang pembobotan ini adalah term yang jarang muncul pada kumpulan dokumen sangat bernilai. Kepentingan tiap term diasumsikan memilki proporsi yang berkebalikan dengan jumlah dokumen yang mengandung term. Faktor IDF dari term t yaitu :
IDF(t) = log( n / df(t) )
Dimana N adalah jumlah seluruh dokumen, df(t) jumlah dokumen yang mengandung term t.
3. TFIDF
Perkalian antara term frequency dan IDF dapat menghasilkan performansi yang lebih baik. Kombinasi bobot dari term t pada dokumen d yaitu :
TDIF(d,t) = TF(d,t) x IDF(t)
Term yang sering muncul pada dokumen tapi jarang muncul pada kumpulan dokumen memberikan nilai bobot yang tinggi. TFIDF akan meningkat dengan jumlah kemunculan term pada dokumen dan berkurang dengan jumlah term yang muncul pada dokumen.
2. Information Retrieval
Information Retrieval (IR) adalah pekerjaan untuk menemukan dokumen yang relevan dengan kebutuhan informasi yang dibutuhkan oleh user. Contoh sistem IR yang paling popular adalah search engine pada World Wide Web. Seorang pengguna Web bisa menginputkan query berupa kata apapun ke dalam sebuah search engine dan melihat hasil dari pencarian yang relevan. Karakteristik dari sebuah sistem IR (Russel & Norvig, 2010) diantaranya adalah:
• A corpus of documents. Setiap sistem harus memutuskan dokumen yang ada akan diperlakukan sebagai apa. Bisa sebagai sebuah paragraf, halaman, atau teks multipage.
• Queries posed in a query language. Sebuah query menjelaskan tentang apa yang user ingin peroleh. Query language dapat berupa list dari kata-kata, atau bisa juga menspesifikasikan sebuah frase dari kata-kata yang harus berdekatan
• A result set. Ini adalah bagian dari dokumen yang dinilai oleh sistem IR sebagai yang relevan dengan query.
• A presentation of the result set. Maksud dari bagian ini adalah tampilan list judul dokumen yang sudah di ranking.
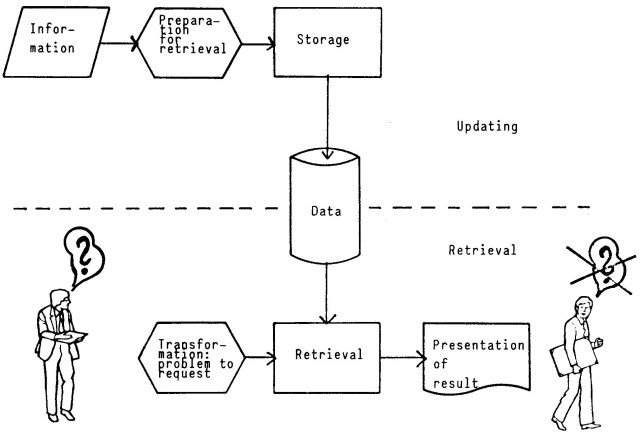
Gambar 2. Proses dari Information Retrieval
Information Retrieval adalah “studi tentang sistem pengindeksan, pencarian, dan mengingat data, khususnya teks atau bentuk tidak terstruktur lainnya.”
[virtechseo.com]
“Information Retrieval adalah seni dan ilmu mencari informasi dalam dokumen, mencari dokumen itu sendiri, mencari metadata yang menjelaskan dokumen, atau mencari dalam database, apakah relasional database itu berdiri sendiri atau database hypertext jaringan seperti Internet atau intranet, untuk teks , suara, gambar, atau data “
[Wikipedia]
Information Retrieval adalah “bidang di persimpangan ilmu informasi dan ilmu komputer. Berkutat dengan pengindeksan dan pengambilan informasi dari sumber informasi heterogen dan sebagian besar-tekstual. Istilah ini diciptakan oleh Mooers pada tahun 1951, yang menganjurkan bahwa diterapkan ke “aspek intelektual” deskripsi informasi dan sistem untuk pencarian (Mooers, 1951). “
[Hersh, 2003]
Secara prinsip, penyimpanan informasi dan penemuan kembali informasi adalah hal yang sederhana. Misalkan terdapat tempat penyimpanan dokumen-dokumen dan seseorang (user) merumuskan suatu pertanyaan (request atau query) yang jawabannya adalah himpunan dokumen yang mengandung informasi yang diperlukan yang diekspresikan melalui pertanyaan user. User bisa saja memperoleh dokumen-dokumen yang diperlukannya dengan membaca semua dokumen dalam tempat penyimpanan, menyimpan dokumen-dokumen yang relevan dan membuang dokumen lainnya. Hal ini merupakan perfect retrieval, tetapi solusi ini tidak praktis. Karena user tidak memiliki waktu atau tidak ingin menghabiskan waktunya untuk membaca seluruh koleksi dokumen, terlepas dari kenyataan bahwa secara fisik user tidak mungkin dapat melakukannya.
Information Retrieval merupakan bagian dari computer science yang berhubungan dengan pengambilan informasi dari dokumen-dokumen yang didasarkan pada isi dan konteks dari dokumen-dokumen itu sendiri. Information Retrieval merupakan suatu pencarian informasi (biasanya berupa dokumen) yang didasarkan pada suatu query (inputan user) yang diharapkan dapat memenuhi keinginan user dari kumpulan dokumen yang ada. Sedangkan, definisi query dalam Information Retrieval menurut referensi merupakan sebuah formula yang digunakan untuk mencari informasi yang dibutuhkan oleh user, dalam bentuk yang paling sederhana, sebuah query merupakan suatu keywords (kata kunci) dan dokumen yang mengandung keywords merupakan dokumen yang dicari dalam IRS.
Proses yang terjadi di dalam Information Retrieval System terdiri dari 2 bagian utama, yaitu Indexing subsystem, dan Searching subsystem (matching system). Proses indexing dilakukan untuk membentuk basisdata terhadap koleksi dokumen yang dimasukkan, atau dengan kata lain, indexing merupakan proses persiapan yang dilakukan terhadap dokumen sehingga dokumen siap untuk diproses. Proses indexing sendiri meliputi 2 proses, yaitu document indexing dan term indexing. Dari term indexing akan dihasilkan koleksi kata yang akan digunakan untuk meningkatkan performansi pencarian pada tahap selanjutnya.
Tahap-tahap yang terjadi pada proses indexing ialah:
1. Word Token,yaitu mengubah dokumen menjadi kumpulan term dengan cara menghapus semua karakter dalam tanda baca yang terdapat pada dokumen dan mengubah kumpulan term menjadi lowercase.
2. Stopword Removal. Proses penghapusan kata-kata yang sering ditampilkan dalam dokumen seperti: and, or, not dan sebagainya.
3. Stemming. Proses mengubah suatu kata bentukan menjadi kata dasar.
4. Term Weighting. Proses pembobotan setiap term di dalam dokumen.
Model IR ada tiga jenis, yaitu :
• Model Boolean : merupakan model IR sederhana yang berdasarkan atas teori himpunan dan aljabar boolean
• Model Vector Space : merupakan model IR yang merepresentasikan dokumen dan query dalam bentuk vektor dimensional
• Model Probabilistic : merupakan model IR yang menggunakan framework probabilistik
Model ruang vektor dan model probabilistik adalah model yang menggunakan pembobotan kata dan perangkingan dokumen. Hasil retrieval yang didapat dari model-model ini adalah dokumen terangking yang dianggap paling relevan terhadap query.
Dalam model ruang vektor, dokumen dan query direpresentasikan sebagai vektor dalam dalam ruang vektor yang disusun dalam indeks term, kemudian dimodelkan dengan persamaan geometri. Sedangkan model probabilistik membuat asumsi-asumsi distribusi term dalam dokumen relevan dan tidak relevan dalam orde estimasi kemungkinan relevansi suatu dokumen terhadap suatu query.
3. HITS Algorithm
Algoritma Hyperlink Induced Topic Search (HITS) Kleinberg memberikan gagasan baru tentang hubungan antara hubs dan authorities. Dalam algoritma HITS, setiap simpul (situs) p diberi bobot hub (xp) dan bobot authority (yp) melalui operasi
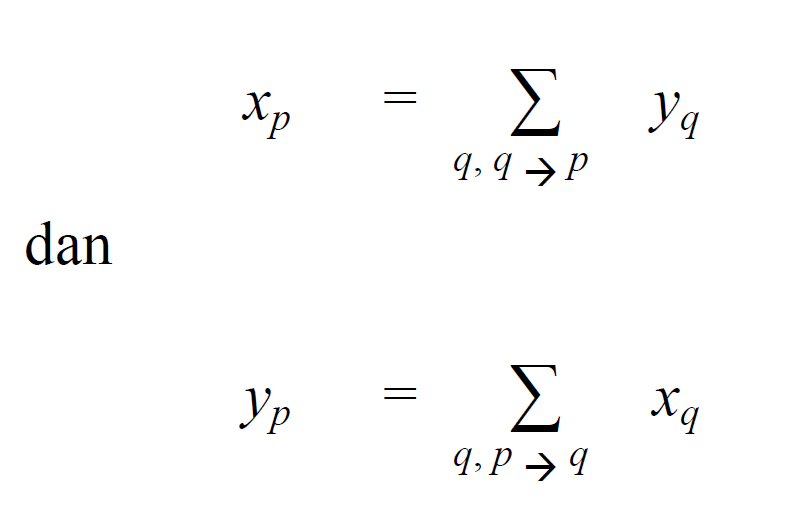
yang dalam hal ini nilai xp diperoleh dari jumlah seluruh nilai yq di mana q adalah situs-situs yang menunjuk (mengandung hyperlink) ke situs p (notasi q p menunjukkan bahwa q menunjuk ke p). Sementara nilai yp diperoleh dari jumlah seluruh nilai xq. Dari operasi tersebut, dapat dilihat bahwa antara hubs dan authorities terdapat sebuah hubungan yang saling memperkuat satu sama lain, yaitu: sebuah hub yang bagus menunjuk ke banyak authorities yang juga bagus, sementara sebuah authority yang bagus ditunjuk oleh banyak hubs yang juga bagus.
Untuk melakukan update secara berkala dari nilai-nilai tersebut, terdapat cara yang lebih singkat dibanding dengan melakukan perhitungan ulang dari rumus yang telah dibahas sebelumnya. Pertama-tama, nomori situs-situs hasil pencarian dengan angka {1,2,…,n} dan tentukan matriks ketetanggaan A yang berukuran n x n dari situs-situs tersebut. Lalu, himpun seluruh nilai x dalam sebuah vektor x = (x1,x2,…,xn) , lakukan hal yang serupa pada seluruh nilai y. Selanjutnya, update nilai x dan y dapat dilakukan melalui operasi
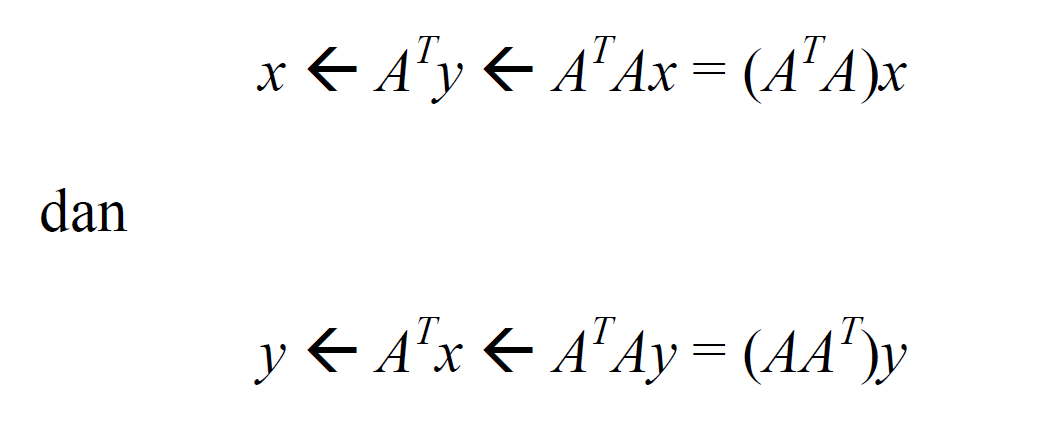
Di bawah ini adalah gambaran keseluruhan dari algoritma HITS.
langkah 1: Kumpulkan sejumlah r situs hasil pencarian sebuah topik yang terletak paling atas (highest-ranked) dari sebuah search engine. Sejumlah r situs ini dikumpulkan dalam sebuah himpunan akar (root) R.
langkah 2: Buatlah sebuah himpunan basis (base) S yang berukuran n, dengan cara memperbesar himpunan R (yaitu, menambah anggota himpunan dengan semua situs yang ditunjuk oleh situs-situs di R dan paling banyak sejumlah d situs tambahan tersebut menunjuk ke situs-situs di R).
langkah 3: Buatlah graf G[S] yang dihasilkan oleh situs-situs pada himpunan S sebagai simpul. Terdapat dua jenis links dalam graf G[S] ini, yaitu: transverse links (links antara situs-situs yang alamat domainnya berbeda) dan intrinsic links (links antara situs-situs yang berdomain sama). Semua sisi yang terbentuk dari intrinsic links dihapus dari graf G[S], sehingga yang tersisa hanyalah sisi-sisi dari transverse links.
langkah 4: Buat matriks ketetanggaan A yang berukuran n x n dan juga matriks transposnya AT. Normalisasikan vektor eigen ε1 dari ATA yang bersesuaian dengan nilai eigen λ1 terbesar.
langkah 5: Temukan elemen-elemen dengan nilai absolut dari hasil normalisasi vektor eigen yang besar. Kemudian, definisikan elemen-elemen tersebut sebagain authorities.
Pada akhirnya, algoritma HITS ini menghasilkan sebuah daftar singkat yang terdiri dari situs-situs dengan bobot hub terbesar serta situs-situs dengan bobot authority terbesar. Yang menarik dari algoritma HITS adalah: setelah memanfaatkan kata kunci (topik yang dicari) untuk membuat himpunan akar (root) R, algoritma ini selanjutnya sama sekali tidak mempedulikan isi tekstual dari situs-situs hasil pencarian tersebut. Dengan kata lain, HITS murni merupakan sebuah algoritma berbasis link setelah himpunan akar terbentuk. Walaupun demikian, secara mengejutkan HITS memberikan hasil pencarian yang baik untuk banyak kata kunci. Sebagai contoh, ketika dites dengan kata kunci ”search engine”, lima authorities terbaik yang dihasilkan oleh algoritma HITS adalah Yahoo!, Lycos, AltaVista, Magellan, dan Excite − padahal tidak satupun dari situs-situs tersebut mengandung kata ”search engine”.
4. Prolog
Sejarah Prolog
– Prolog singkatan dari Programming in Logic.
– Dikembangkan oleh Alain Colmenraurer dan P.Roussel di Universitas Marseilles Perancis, tahun1972.
– Prolog populer di Eropa untuk aplikasi artificial intelligence, sedangkan di Amerika peneliti mengembangkan aplikasi yang sama, yaitu LISP.
Perbedaan Prolog dengan Bahasa Lainnya
– Bahasa Pemrograman yang Umum (Basic, Pascal, C, Fortran):
o diperlukan algoritma/prosedur untuk memecahkan masalah (procedural languange)
o program menjalankan prosedur yang sama berulang-ulang dengan data masukan yang berbeda-beda.
o Prosedur dan pengendalian program ditentukan oleh programmer dan perhitungan dilakukan sesuai dengan prosedur yang telah dibuat.
– Bahasa Pemrograman Prolog :
o Object oriented languange atau declarative languange.
o Tidak terdapat prosedur, tetapi hanya kumpulan data-data objek (fakta) yang akan diolah, dan relasi antar objek tersebut membentuk aturan yang diperlukan untuk mencari suatu jawaban
o Programmer menentukan tujuan (goal), dan komputer menentukan bagaimana cara mencapai tujuan tersebut serta mencari jawabannya.
o Dilakukan pembuktian terhadap cocok-tidaknya tujuan dengan data-data yang telah ada dan relasinya.
o Prolog ideal untuk memecahkan masalah yang tidak terstruktur, dan prosedur pemecahannya tidak diketahui, khususnya untuk memecahkan masalah non numerik.
o Prolog bekerja seperti pikiran manusia, proses pemecahan masalah bergerak di dalam ruang masalah menuju suatu tujuan (jawaban tertentu).
o Contoh : Pembuatan program catur dengan Prolog
Aplikasi Prolog :
– Sistem Pakar (Expert System)
Program menggunakan teknik pengambilan kesimpulan dari data-data yang didapat, layaknya seorang ahli.
Contoh dalam mendiagnosa penyakit
– Pengolahan Bahasa Alami (Natural Languange Processing)
Program dibuat agar pemakai dapat berkomunikasi dengan komputer dalam bahasa manusia sehari-hari, layaknya penterjemah.
– Robotik
Prolog digunakan untuk mengolah data masukanyang berasal dari sensor dan mengambil keputusan untuk menentukan gerakan yang harus dilakukan.
– Pengenalan Pola (Pattern Recognition)
Banyak digunakan dalam image processing, dimana komputer dapat membedakan suatu objek dengan objek yang lain.
– Belajar (Learning)
Program belajar dari kesalahan yang pernah dilakukan, dari pengamataqn atau dari hal-hal yang pernah diminta untuk dilakukan.
Fakta dan Relasi
– Prolog terdiri dari kumpulan data-data objek yang merupakan suatu fakta.
– Fakta dibedakan 2 macam :
o Menunjukkan relasi.
o Menunjukkan milik/sifat.
– Penulisannya diakhiri dengan tanda titik “.”
– Contoh :

Aturan (“Rules”)
– Aturan adalah suatu pernyataan yang menunjukkan bagaimana fakta-fakta berinteraksi satu dengan yang lain untuk membentuk suatu kesimpulan.
– Sebuah aturan dinyakatakan sebagai suatu kalimat bersyarat.
– Kata “if” adalah kata yang dikenal Prolog untuk menyatakan kalimat bersyarat atau disimbolkan dengan “:-“.
– Contoh :

– Setiap aturan terdiri dari kesimpulan(kepala) dan tubuh.
– Tubuh dapat terdiri dari 1 atau lebih pernyataan atau aturan yang lain, disebut subgoal dan dihubungkan dengan logika “and”.
– Aturan memiliki sifat then/if conditional
“Kepala(head) benar jika tubuh (body) benar”.
– Contoh : Silsilah keluarga :
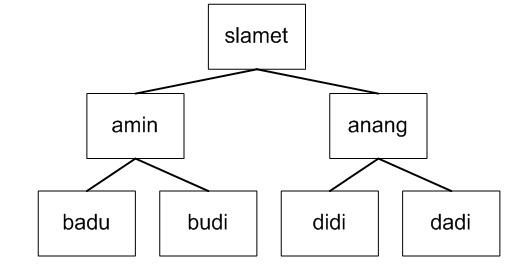

Pertanyaan (“Query”)
– Setelah memberikan data-data berupa fakta dan aturan, selanjutnya kita dapat mengajukan pertanyaan berdasarkan fakta dan aturan yang ada.
– Penulisannya diawali simbol “?-“ dan diakhiri tanda “.”.
– Contoh :

Predikat (“Predicate”)
– Predikat adalah nama simbolik untuk relasi.
– Contoh : ayah(slamet,amin).
Predikat dari fakta tersebut ditulis : ayah(simbol,simbol).
dimana ayah adalah nama predikat, sedangkan slamet dan amin adalah menujukkan argumen.
Sebuah predikat dapat tidak memiliki atau memiliki argumen dengan jumlah bebas. Jumlah argumen suatu predikat disebut aritas (arity).
ayah(nama) …… aritas-nya 1
ayah(nama1,nama2) ….. aritasnya 2
– Syarat-syarat penulisan nama predikat :
o Harus diawali dengan huruf kecil dan dapat diikuti dengan huruf, bilangan atau garis bawah.
o Panjang nama predikat maksimum 250 karakter.
o Tidak diperbolehkan menggunakan spasi, tanda minus, tanda bintang dan garis miring.
Variabel
– Varibel adalah besaran yang nilainya dapat berubah-ubah.
– Tata cara penulisan variabel :
1. Nama varibel harus diawali huruf besar atau garis bawah(_)
2. Nama variabel dapat terdiri dari huruf, bilangan, atau simbol dan merupakan kesatuan dengan panjang maksimum 250 karakter.
3. Nama variabel hendaknya mengandung makna yang berkaitan dengan data yang dinyatakannya.
– Contoh : dari silsilah di atas :
?- ayah(slamet,Anak).
Anak=budi ;
Anak=badu
No
Dari query di atas akan dicari siapakah anak dari ayah yang bernama Slamet. Karena mempunyai relasi yang sama (yaitu ayah), variabel Anak akan mencari nilai dari konstanta suatu fakta/aturan yang sepadan.
Tanda “;” digunakan bila terdapat kemungkinan ada lebih dari satu jawaban.
“No” berarti tidak ada lagi kemungkinan jawaban.
Contoh : dari silsilah di atas :
?- ayah(slamet,X),ayah(X,Y).
X=amin
Y=budi ;
X=amin
Y=badu ;
X=anang
Y=didi ;
X=anang
Y=didi
No
Contoh : Silsilah Keluarga
%% FAKTA */
%%orang tua */
ayah(slamet,amin).
ayah(slamet,anang).
ayah(amin,budi).
ayah(amin,badu).
ayah(anang,didi).
ayah(anang,dadi).
ayah(santoso,bu_amin).
ayah(supardi,bu_anang).
ibu(bu_slamet,amin).
ibu(bu_slamet,anang).
ibu(bu_amin,budi).
ibu(bu_amin,badu).
ibu(bu_anang,didi).
ibu(bu_anang,dadi).
ibu(bu_santoso,bu_amin).
ibu(bu_santoso,bu_anang).
%% ATURAN */
%% Kakek adalah kakek Cucu */
kakek(Kakek,Cucu) :-
ayah(Ayah,Cucu),
ayah(Kakek,Ayah).
kakek(Kakek,Cucu) :-
ibu(Ibu,Cucu),
ayah(Kakek,Ibu).
%% Nenek adalah nenek Cucu */
nenek(Nenek,Cucu) :-
ayah(Ayah,Cucu),
ibu(Nenek,Ayah).
nenek(Nenek,Cucu) :-
ibu(Ibu,Cucu),
ibu(Nenek,Ibu).
%% Nama1 adalah saudara kandung Nama2
saudara_kandung(Nama,Name) :-
ayah(Ayah,Nama),
ayah(Ayah,Name),
ibu(Ibu,Nama),
ibu(Ibu,Name),
Nama \= Name.
%% Sdr1 adalah saudara sepupu Sdr2
saudara_sepupu(Sdr1,Sdr2) :-
ayah(Ayah1,Sdr1),
ayah(Ayah2,Sdr2),
saudara_kandung(Ayah1,Ayah2).
saudara_sepupu(Sdr1,Sdr2) :-
ayah(Ayah,Sdr1),
ibu(Ibu,Sdr2),
saudara_kandung(Ayah,Ibu).
saudara_sepupu(Sdr1,Sdr2) :-
ibu(Ibu,Sdr1),
ayah(Ayah,Sdr2),
saudara_kandung(Ibu,Ayah).
saudara_sepupu(Sdr1,Sdr2) :-
ibu(Ibu1,Sdr1),
ibu(Ibu2,Sdr2),
saudara_kandung(Ibu1,Ibu2).
————————————————————————————————————————–———-—–
Tugas T0264 – Intelegensia Semu GSLC 2 (8 Mei 2014)
012 years
Learning from Examples I
Tugas berhubungan dengan pertemuan sesi 17 Learning by Example
1. Apa yang dimaksud supervised learning, unsupervised learning dan reinforcement learning? berikan contoh masing-masing?
– Supervised learning : merupakan suatu pembelajaran yang terawasi dimana jika output yang diharapkan telah diketahui sebelumnya. Biasanya pembelajaran ini dilakukan dengan menggunakan data yang telah ada.
Atau
teknik pembelajaran mesin dengan membuat suatu fungsi dari data latihan. Data latihan terdiri dari pasangan nilai input dan output yang diharapkan dari input yang bersangkutan. Tugas dari Supervised learning adalah untuk memprediksi nilai fungsi untuk nilai semua input yang ada.
Contoh :
– Sebagai contoh ada data luas rumah (x) dan harga (y). lalu dimasukkan dalam grafik x dan y-nya. Dimana setelah itu dibuat regresi antara x dan y-nya. Setelah membuat regresi dapat dipastikan kita dapat memprediksi dari hasil regresi harga rumah dengan luas tertentu.
– Contoh algoritma jaringan saraf tiruan yang mernggunakan metode supervised learning adalah hebbian (hebb rule), perceptron, adaline, boltzman, hapfield, dan backpropagation.
– Misalnya sebuah program diberikan benda berupa bangku dan meja, maka setelah beberapa contoh, program tersebut harus dapat memilah- milah objek ke dalam klasifikasi yang cocok. Kesulitan dari supervised learning adalah kita tidak dapat membuat klasifikasi yang benar. Dapat dimungkinkan program akan salah dalam mengklasifikasi sebuah objek setelah dilatih. Oleh karena itu, selain menggunakan training set kita juga memberikan test set. Dari situ kita akan mengukur persentase keberhasilannya. Semakin tinggi berarti semakin baik program tersebut. Persentase tersebut dapat ditingkatkan dengan diketahuinya temporal dependence dari sebuah data. Misalnya diketahui bahwa 70% mahasiswa dari jurusan Teknik Informatika adalah laki- laki dan 80% mahasiswa dari jurusan Sastra adalah wanita. Maka program tersebut akan dapat mengklasifikasi dengan lebih baik.

– Unsupervised learning : merupakan pembelajan yang tidak terawasi dimana tidak memerlukan target output. Pada metode ini tidak dapat ditentukan hasil seperti apa yang diharapkan selama proses pembelajaran, nilai bobot yang disusun dalam proses range tertentu tergantung pada nilai output yang diberikan. Tujuan metode uinsupervised learning ini agar kita dapat mengelompokkan unit-unit yang hampir sama dalam satu area tertentu. Pembelajaran ini biasanya sangat cocok untuk klasifikasi pola.
Atau
Teknik ini menggunakan prosedur yang berusaha untuk mencari partisi dari sebuah pola. Unsupervised learning mempelajari bagaimana sebuah sistem dapat belajar untuk merepresentasikan pola input dalam cara yang menggambarkan struktur statistikal dari keseluruhan pola input. Berbeda dari supervised learning, unsupervised learning tidak memiliki target output yang eksplisit atau tidak ada pengklasifikasian input.
Dalam machine learning, teknik unsupervised sangat penting. Hal ini dikarenakan cara bekerjanya mirip dengan cara bekerja otak manusia. Dalam melakukan pembelajaran, tidak ada informasi dari contoh yang tersedia. Oleh karena itu, unsupervised learning menjadi esensial.
Contoh :
– Contoh algoritma jaringan saraf tiruan yang menggunakan metode unsupervised ini adalah competitive, hebbian, kohonen, LVQ(Learning Vector Quantization), neocognitron.
– Competitive learning, di mana neuron-neuron saling bersaing untuk menjadi pemenang.
– Ilustrasi yang mudah misalkan hubungan antara murid dan dosen pada contoh yang sebelumnya. Ketika si murid menjumpai masalah, ia harus dapat menjawab masalah tersebut dengan sendirinya. Semakin banyak ia berusaha menjawab sendiri, ia akan semakin pandai dalam menemukan rule yang dapat digunakan untuk memecahkan permasalahan di kemudian hari.

– Reinforcement learning : Konsep dasar reinforcement learning diambil dari suatu teori dalam ilmu psikologi yang disebut dengan reinforcement theory. Reinforcement theory ini merupakan suatu pendekatan psikologi yang sangat penting bagi manusia. Teori ini menjelaskan bagaimana seseorang itu dapat menentukan, memilih dan mengambil keputusan dalam dinamika kehidupan. Kelebihan lain dari teori ini dapat digunakan pada berbagai macam situasi yang seringkali dihadapi manusia (Bertsekas, 1996 : 2).
Menurut Masayu Leylia (2003:2) reinforcement learning merupakan pembelajaran hasil interaksi dengan lingkungan, sehingga dapat diperoleh maximal cummulative reward saat goal tercapai. Hal senada diungkapkan oleh Ali Ridho Barakbah (2007:3-6) reinforcement learning adalah salah satu paradigma baru di dalam learning theory. Reinforcement learning dibangun dari proses mapping (pemetaan) dari situasi yang ada di environment (states) ke bentuk aksi (behavior) agar dapat memaksimalkan reward. Reinforcement learning secara umum terdiri dari 4 komponen dasar, yaitu: (a) policy : kebijaksanaan, (b) reward function, (c) value function, dan (d) model of environment.
Contoh :
– Contoh yang realistis, AI dalam permainan, seperti catur atau monopoli. Kalau agen itu pintar dan menang, di dapat hadiah, atau sekedar ucapan ‘Selamat Anda Menang’ dan kalau kalah tentu saja ucapan yang berlawanan.
– Contoh yang paling mudah yang bisa saya gambarkan disini adalah bagaimana sikap yang diambil oleh seorang siswa di dalam kelas. Asumsikan bahw a sang guru sudah menjelaskan seperangkap aturan yang harus ditaati oleh siswa di dalam kelas. Suatu ketika, seorang siswa berteriak di dalam kelas. Maka sang guru langsung memberikan hukuman kepada siswa tersebut. Dari hukuman itu, siswa tadi akan merubah sikapnya untuk tidak berteriak lagi. Juga demikian, kepada siswa yang tekun mengikuti pelajaran di dalam kelas, maka sang guru memberikan kepada mereka semacam hadiah atau penghargaan. Jika sistem ini berjalan dalam jangka waktu tertentu, maka keadaan siswa tadi pasti akan konvergen untuk mengambil sikap yang baik di dalam kelas.
2. Apa yang dimaksud dengan Learning Decision Tree dan berikan contohnya?
– Secara singkat bahwa Decision Tree merupakan salah satu metode klasifikasi pada Text Mining. Klasifikasi adalah proses menemukan kumpulan pola atau fungsi-fungsi yang mendeskripsikan dan memisahkan kelas data satu dengan lainnya, untuk dapat digunakan untuk memprediksi data yang belum memiliki kelas data tertentu (Jianwei Han, 2001).
– Decision Tree adalah sebuah struktur pohon, dimana setiap node pohon merepresentasikan atribut yang telah diuji, setiap cabang merupakan suatu pembagian hasil uji, dan node daun (leaf) merepresentasikan kelompok kelas tertentu. Level node teratas dari sebuah Decision Tree adalah node akar (root) yang biasanya berupa atribut yang paling memiliki pengaruh terbesar pada suatu kelas tertentu. Pada umumnya Decision Tree melakukan strategi pencarian secara top-down untuk solusinya. Pada proses mengklasifikasi data yang tidak diketahui, nilai atribut akan diuji dengan cara melacak jalur dari node akar (root) sampai node akhir (daun) dan kemudian akan diprediksi kelas yang dimiliki oleh suatu data baru tertentu.
Contoh :
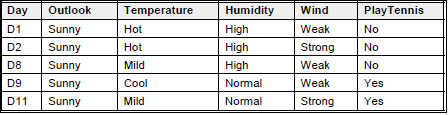
Beberapa Terms Examples (S), adalah training examples yang ditunjukkan oleh tabel di bawah ini:
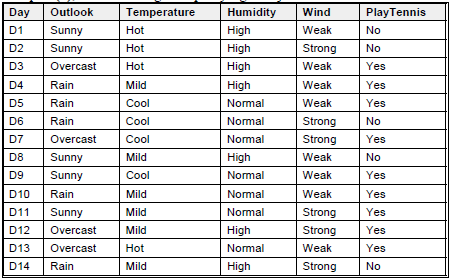
Target attribute adalah PlayTennis yang memiliki value yes atau no, selama 14 minggu pada setiap Sabtu pagi. Attribute adalah Outlook, Temperature, Hunidity, dan Wind.
Algoritma
PROCEDURE ID3(Examples, TargetAttribute, Attributes)5
Examples are the training examples. Target-attribute is the attribute whose value is to be
predicted by the tree. Attributes is a list of other attributes that may be tested by the
learned decision tree. Returns a decision tree that correctly classifies the given Examples.
• Create a Root node for the tree
• If all Examples are positive, Return the single-node tree Root, with label = +
• If all Examples are negative, Return the single-node tree Root, with label = –
• If Attributes is empty, Return the single-node tree Root, with label = most common
value of Target_attribute in Examples
• Otherwise Begin
• A <— the attribute from Attributes that best* classifies Examples
• The decision attribute for Root <— A
• For each possible value, vi, of A,
• Add a new tree branch below Root, corresponding to the test A = vi
• Let Examplesvi be the subset of Examples that have value vi for A
• If Examplesvi is empty
• Then below this new branch add a leaf node with label = most common
• value of Target_attribute in Examples
• Else below this new branch add the subtree
• Call ID3 (Examples, Target_attribute, Attributes – {A}))
• End
• Return Root
The best attribute is the one with highes information gain, as defined in Equation:
![]()
S adalah koleksi dari 14 contoh dengan 9 contoh positif dan 5 contoh negatif, ditulis dengan notasi [9+,5-]. Entropy dari S adalah:
![]()
Entropy([9+,5-]) = – (9/14)log2(9/14) – (5/14)log2(5/14)
= 0.94029
Catatan:
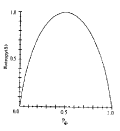
• Entropy(S)=0, jika semua contoh pada S berada dalam kelas yang sama.
• Entropy(S)=1, jika jumlah contoh positif dan jumlah contoh negatif dalam S adalah sama.
• 0<Entropy(S)<1, jika jumlah contoh positif dan negatif dalam S tidak sama.
Gain(S,A) adalah Information Gain dari sebuah attribute A pada koleksi contoh S.6
Values(Wind) = Weak, Strong
SWeak = [6+,2-]
SStrong = [3+,3-]
Gain(S,Wind) = Entropy(S) – (8/14)Entropy(SWeak) – (6/14)Entropy(SStrong)
= 0.94029 – (8/14)0.81128 – (6/14)1.0000
= 0.04813
Values(Humidity) = High, Normal
SHigh = [3+,4-]
SNormal = [6+,1-]
Gain(S,Humidity) = Entropy(S) – (7/14)Entropy(SHigh) – (7/14)Entropy(SNormal)
= 0.94029 – (7/14)0.98523 – (7/14)0.59167
= 0.15184
Values(Temperature) = Hot, Mild, Cool
SHot = [2+,2-]
SMild = [4+,2-]
SCool = [3+,1-]
Gain(S,Temperature) = Entropy(S) – (4/14)Entropy(SHot) – (6/14)Entropy(SMild)- (4/14)Entropy(SCool)
= 0.94029 – (4/14)1.00000 – (6/14)0.91830 – (4/14)0.81128
= 0.02922
Values(Outlook) = Sunny, Overcast, Rain
SSunny = [2+,3-]
SOvercast = [4+,0-]
SRain = [3+,2-]
Gain(S,Outlook) = Entropy(S) – (5/14)Entropy(SSunny) – (4/14)Entropy(SOvercast)
-(5/14)Entropy(SRain)
= 0.94029 – (5/14)0.97075 – (4/14)1.000000 – (5/14)0.97075
= 0.24675
Jadi, information gain untuk 4 atribut yang ada adalah:
Gain(S,Wind) = 0.04813
Gain(S,Humidity) = 0.15184
Gain(S,Temperature) = 0.02922
Gain(S,Outlook) = 0.24675
Dari perhitungan tersebut, tampak bahwa attribute Outlook akan menyediakan prediksi terbaik untuk target attribute PlayTennis.
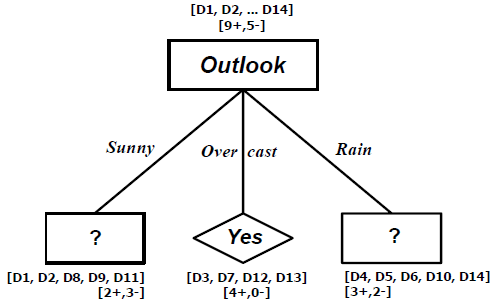
Untuk branch node Outlook=Sunny,
SSunny = [D1, D2, D8, D9, D11]
Values(Temperature) = Hot, Mild, Cool
SHot = [0+,2-]
SMild = [1+,1-]
SCool = [1+,0-]
Gain(SSunny, Temperature) = Entropy(SSunny) – (2/5)Entropy(SHot) – (2/5)Entropy(SMild)
– (1/5)Entropy(SCold)
= 0.97075 – (2/5)0.00000 – (2/5)1.00000 – (1/5)0.00000
= 0.57075
Values(Humidity) = High, Normal
SHigh = [0+,3-]
SNormal = [2+,0-]
Gain(SSunny, Humidity) = Entropy(SSunny) – (3/5)Entropy(SHigh) – (2/5)Entropy(SNormal)
= 0.97075 – (3/5)0.00000 – (2/5)1.00000
= 0.97075
Values(Wind) = Weak, Strong
SWeak = [1+,2-]
SStrong = [1+,1-]
Gain(SSunny, Wind) = Entropy(SSunny) – (3/5)Entropy(SWeak) – (2/5)Entropy(SStrong)
= 0.97075 – (3/5)0.91830 – (2/5)1.00000
= 0.01997
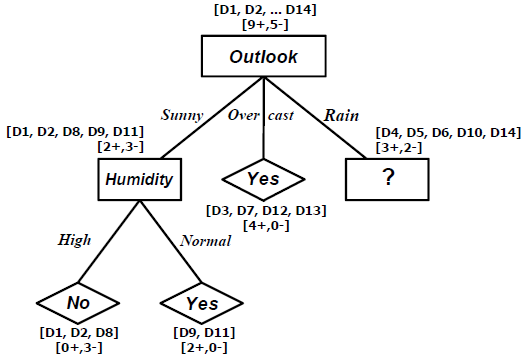
Untuk branch node Outlook=Rain,
SRain = [D4, D5, D6, D10, D14]
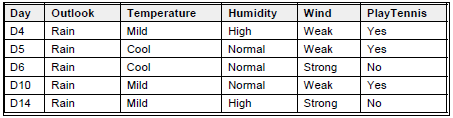
Values(Temperature) = Mild, Cool {Tidak ada lagi temperature=hot saat ini}
SMild = [2+,1-]
SCool = [1+,1-]
Gain(SRain, Temperature) = Entropy(SRain) – (3/5)Entropy(SMild) – (2/5)Entropy(SCold)
= 0.97075 – (3/5)0.91830 – (2/5)1.00000
= 0.01997
Values(Humidity) = High, Normal
SHigh = [1+,1-]
SNormal = [2+,1-]
Gain(SRain, Humidity) = Entropy(SRain) – (2/5)Entropy(SHigh) – (3/5)Entropy(SNormal)
= 0.97075 – (2/5)1.00000 – (3/5)0.91830
= 0.01997
Values(Wind) = Weak, Strong
SWeak = [3+,0-]
SStrong = [0+,2-]
Gain(SRain, Wind) = Entropy(SRain) – (3/5)Entropy(SWeak) – (2/5)Entropy(SStrong)
= 0.97075 – (3/5)0.00000 – (2/5)0.00000
= 0.97075
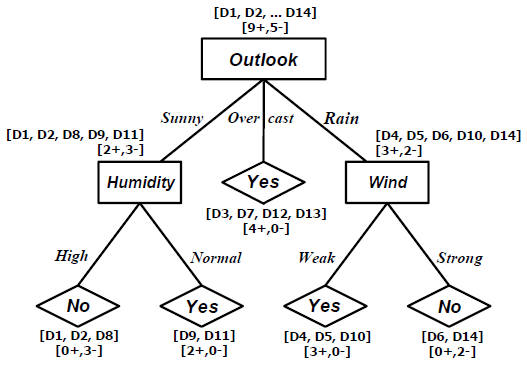
Rule-Rule yang telah Dipelajari, dengan memperhatikan decision tree yang dihasilkan adalah :
• IF Outlook = Sunny AND Humidity = High THEN PlayTennis = No
• IF Outlook = Sunny AND Humidity = Normal THEN PlayTennis = Yes
• IF Outlook = Overcast THEN PlayTennis = Yes
• IF Outlook = Rain AND Wind = Strong THEN PlayTennis = No
• IF Outlook = Rain AND Wind = Weak THEN PlayTennis = Yes
———————————————————————————————————————————–
Pre Mid Term Project of Group 3 – Sistem Multimedia
012 years
T0553 – SISTEM MULTIMEDIA
LAPORAN PEMBUATAN VIDEO
04PLT
Kelompok 3:
David Febryanto (1601222070)
Edward Ivan Fadli (1601218874)
Sudiarto Winata (1601223786)
Kenzu Pangestu (1601224864)
Wira Adi Putra(1601223451)
————————————————————————————————————————————
1. Latar Belakang dan Deskripsi video
Setiap film pasti mempunyai genre. Genre tersebut bisa saja action, romantic, drama, comedy, bahkan horror. Disini saya akan membahas salah satu dari genre tersebut yang saya anggap cukup menarik untuk dibahas, yaitu genre horror.
Horror, seperti yang kita ketahui adalah genre yang memang berbau “seram” atau dapat memancing rasa takut pada diri kita. Horror biasanya diaplikasikan melalui suatu film yang memiliki sebuah cerita yang menyeramkan dan penuh misteri akan kematian, baik itu fiksi ataupun kenyataan. Biasanya ada beberapa film horror yang memang “based on true story” atau cerita nyata yang membuat penontonnya semakin merasakan aura yang menakutkan.
Namun disini saya akan membahas lebih kepada pengaplikasian genre horror ke dalam bentuk video singkat. Video singkat yang kami (kelompok 3) buat berisikan tentang 5 film horror terbaik dimana setiap filmnya kami berikan rating secara rata-rata beserta review singkat. Untuk penilaian film horror yang kami buat, setiap anggota kelompok kami (termasuk saya) menilai setiap film sesuai masing-masing persepsi sehingga lebih fair dan akan memberikan hasil nilai yang lebih subjektif.
Video singkat yang kami buat ini bertujuan agar para penonton yang sudah menonton ataupun yang belum dapat menyaksikan beberapa film horror yang sudah kami rekomendasikan. Film horror yang kami rekomendasikan semuanya sudah pernah tayang di layar lebar / bioskop sehingga kualitas film yang ditayangkan setidaknya memang terjamin “horror”nya (namun semuanya kembali kepada persepsi setiap penonton).
Kami juga ingin membuat para penonton tetap dapat menikmati film horror, karena film horror tidak selalu menimbulkan efek negatif bagi seseorang. Penonton dapat merasakan efek positif seperti menguji adrenalinnya dan memiliki keberanian yang lebih dalam kehidupan sehari-hari. Memicu adrenalin dapat membuat penonton lebih sigap dan siaga dalam keadaan apapun. Jadi menurut kami, film horror merupakan salah satu genre film yang menarik, walaupun beberapa orang mungkin tidak menyukai film horror (mempunyai phobia terhadap hantu yang berlebihan.
2. Spesifikasi Video
Video singkat yang kami buat berdurasi : 9 menit 57 detik, dimana isi dari video singkat tersebut terdiri dari Introduction atau pengenalan anggota kelompok kami, kemudian dilanjutkan dengan Content Video tersebut yang berisi 5 film horror terbaik menurut versi kami beserta rating masing-masing film dan juga review dari setiap anggota kelompok kami. Akhirnya, video singkat tersebut kami tutup dengan Credits yang berisi tentang peran dari anggota kelompok kami dalam pembuatan film tersebut beserta detail video. Perlu diketahui bahwa video singkat yang kami buat menggunakan software SONY Vegas Movie Studio HD Platinum (v.11.0).
3. Tujuan
Tujuan kami membuat video bertemakan horror :
- Mencoba menciptakan kreasi video baru yang berbeda dari yang pernah ada
- Membuat referensi movie horror yang update yang memberikan penilaian
- Menjadikan video ini sebagai media hiburan
4. Storyboard and Documentation
Berikut adalah dokumentasi dari pembuatan video beserta beberapa bagian pada kontennya :

Kami menggunakan Sony Vegas Movie Studio HD Platinum untuk software utama video editing
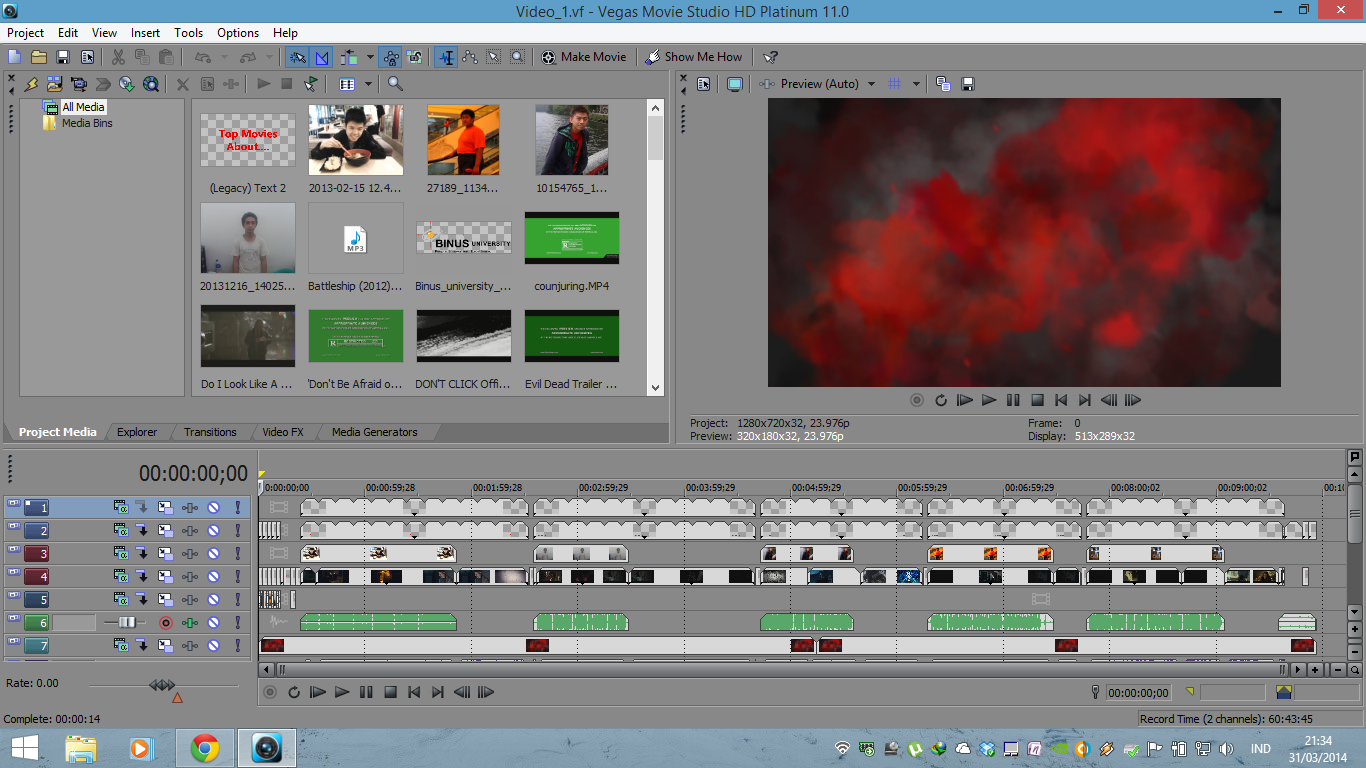
Tampilan Sony Vegas Movie Studio HD Platinum
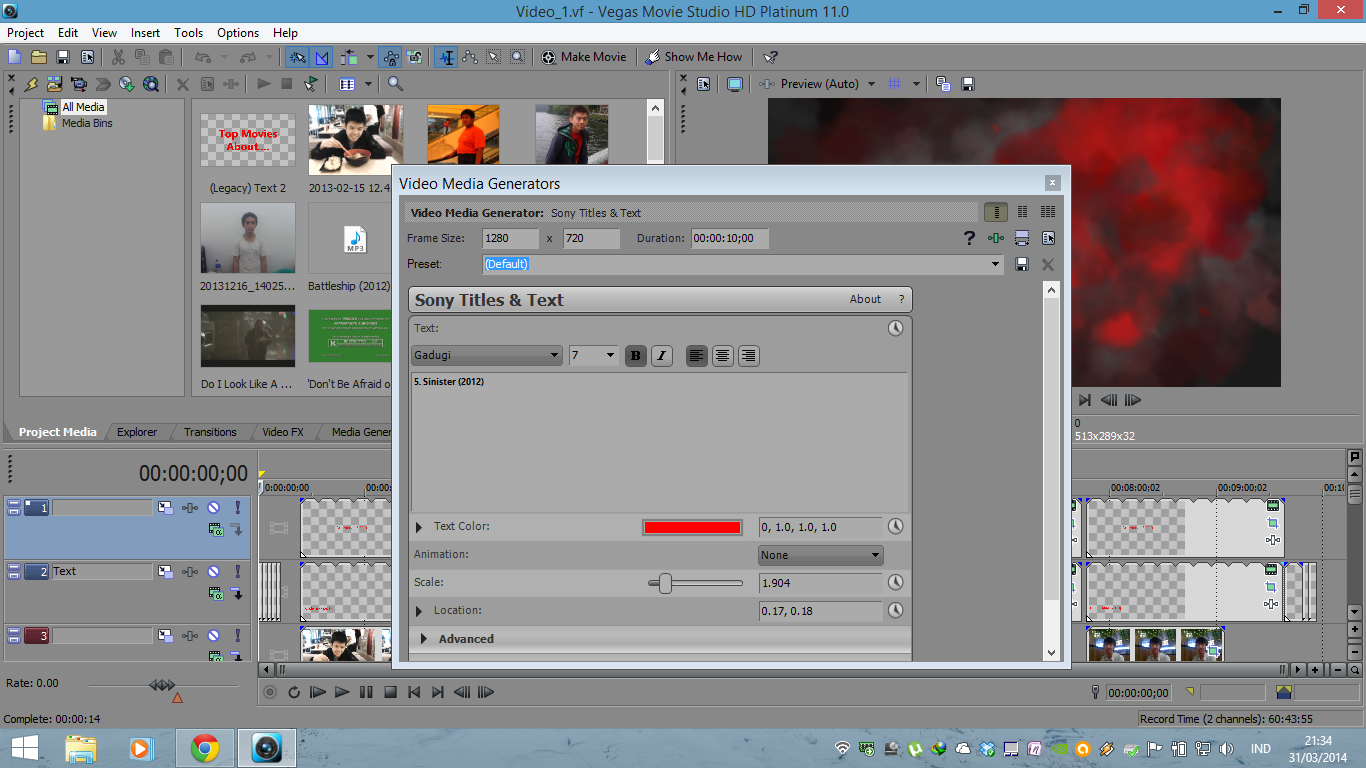
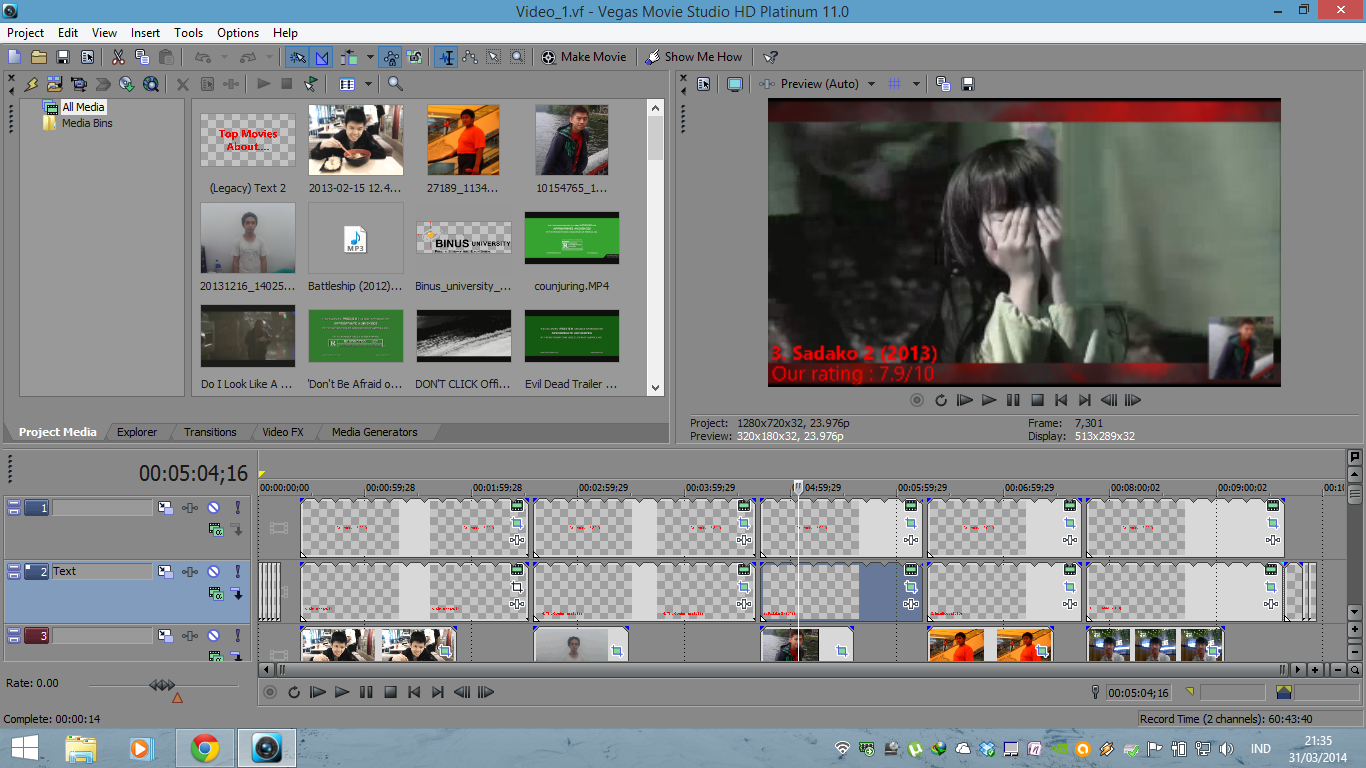
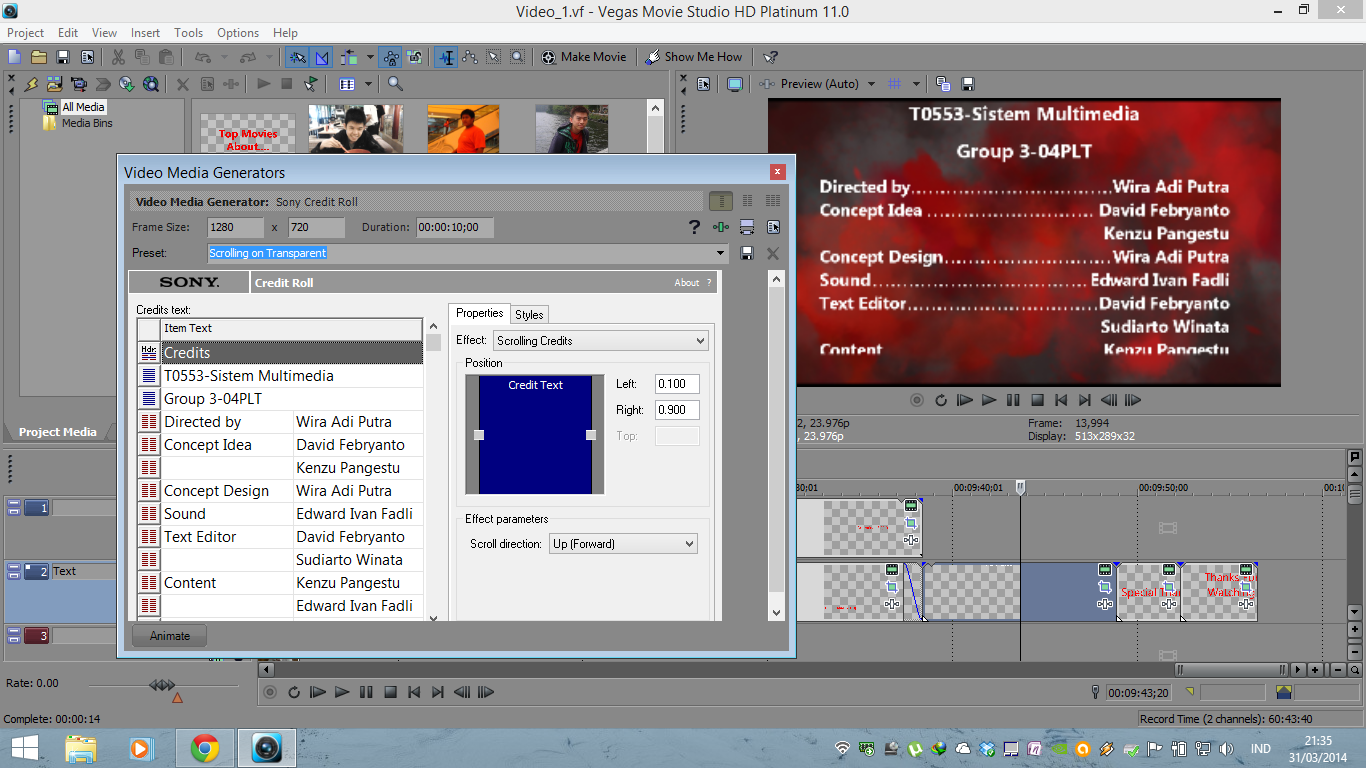
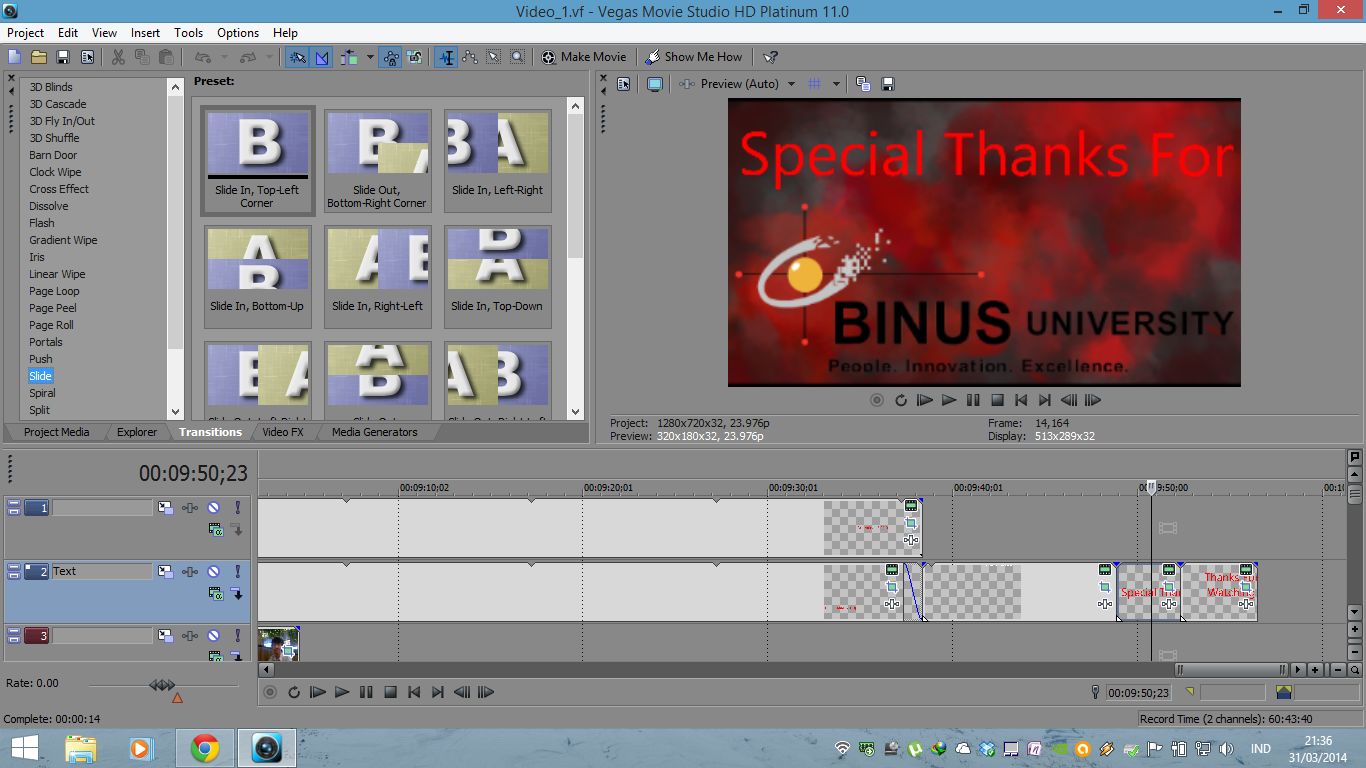
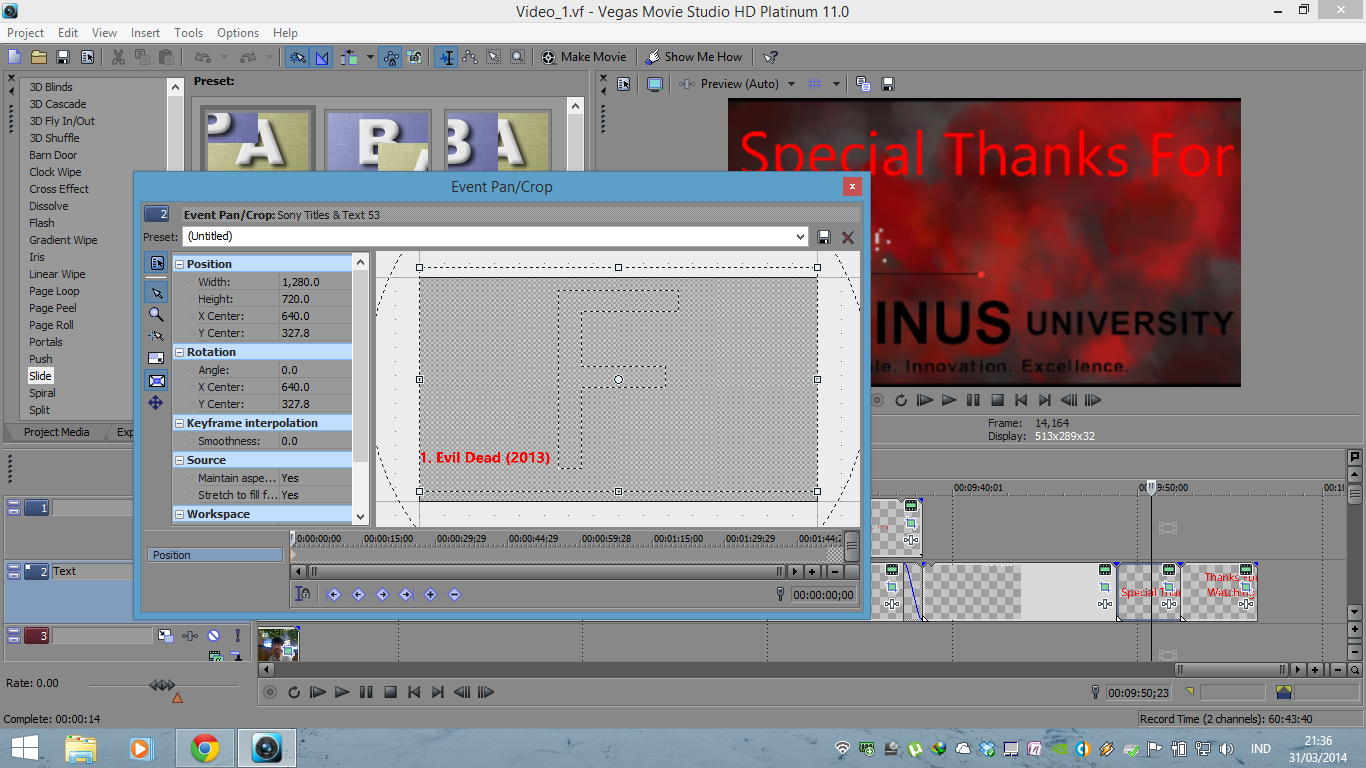
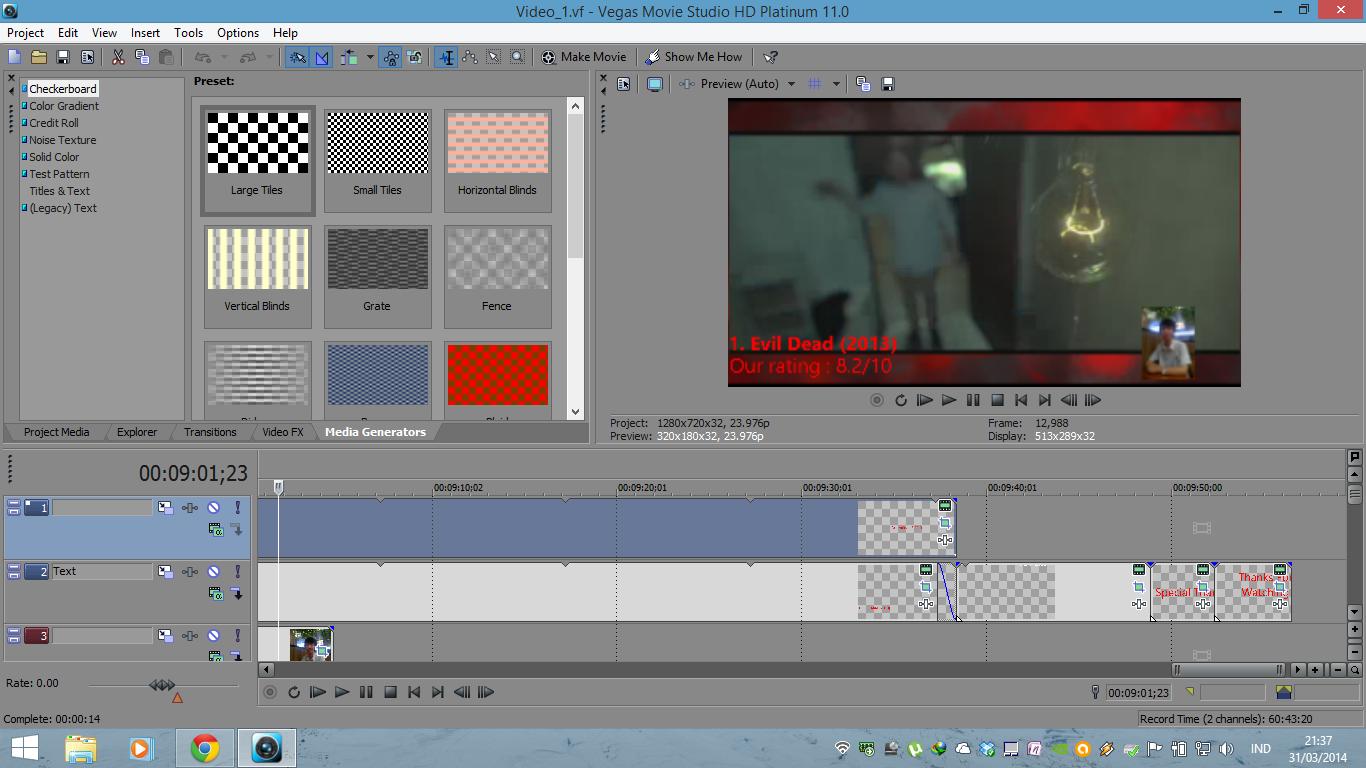
Proses pembuatan video

Salah satu scene intro video kami

{kind=link}
Kumpulan Screenshot berbagai Scene
Video :
http://www.youtube.com/watch?v=mNh9CRYwbZE
Link Video : http://youtu.be/mNh9CRYwbZE
Tugas T0264 – Intelegensia Semu GSLC 1 (13 Maret 2014)
012 years
Adversarial Search & Constraint Satisfaction Problems
Soal :
1. Apa yang dimaksud Adversarial Search & Constraint Satisfaction Problems ? berikan contoh ?
2. Apa itu Propositional Logic ? berikan contoh ?
3. Buat coding (Boleh C, C++ atau Java) untuk Algoritma A & Algoritma A* (A Star )?
Jawaban :
1. – Adversarial Search :
Algoritma pencarian yang memeriksa masalah yang timbul ketika kita mencoba untuk merencanakan suatu langkah ke depan tetapi ada agen-agen lain berencana melawan kita.
atau
Algoritma pencarian yang digunakan dalam permainan di mana satu pemain mencoba untuk memaksimalkan nilai mereka (menang) tetapi ditentang oleh pemain lain ( AI, Player Computer ).
biasa digunakan untuk pencarian dalam game ( Catur, Tic Tac Toe, dll.)
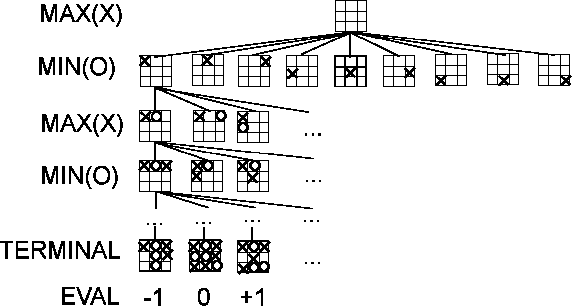
Algoritma yang biasa digunakan : MiniMax, Alpha–beta pruning.
Gambar Algoritma Minimax :
– Constraint Satisfaction Problems :
Sebuah pendekatan dari problem yang bersifat matematis dengan tujuan menemukan keadaan atau obyek yang memenuhi sejumlah persyaratan atau kiteria. Sebuah Constraint diartikan sebagai batasan solusi memungkinkan dalam sebuah problem optimasi.
Singkatnya menyelesaikan masalah dengan pemenuhan batasan.
Contoh masalah sederhana yang dapat dimodelkan dengan CSP :
- Eight queens puzzle
- Map coloring problem
- Sudoku, Futoshiki, Kakuro (Cross Sums), Numbrix, Hidato and many other logic puzzles.

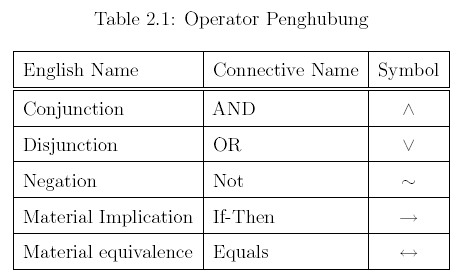
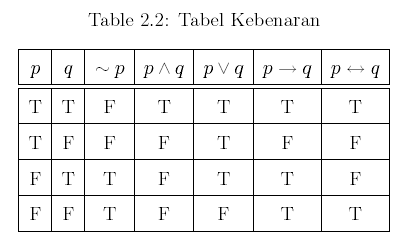
2. Propositional logic merupakan salah satu bentuk (bahasa) representasi logika yang paling tua dan paling sederhana. Dengan cara ini beberapa fakta dapat digambarkan dan dimanipulasi dengan menggunakan aturan-aturan aljabar Boolean.

Contoh :
Jika seseorang itu adalah mahasiswa maka ia pasti pandai
Dian Sastro adalah seorang mahasiswa
——————————————————————————–
Dian Sastro pasti pandai
p = mahasiswa
q = pandai
p -> q
p
———
q
3. – Best – First / Algoritma A :
[code language=”css”]
import java.util.Comparator;
import java.util.InputMismatchException;
import java.util.PriorityQueue;
import java.util.Scanner;
public class BestFirstSearch
{
private PriorityQueue<Vertex> priorityQueue;
private int heuristicvalues[];
private int numberOfNodes;
public static final int MAX_VALUE = 999;
public BestFirstSearch(int numberOfNodes)
{
this.numberOfNodes = numberOfNodes;
this.priorityQueue = new PriorityQueue<Vertex>(this.numberOfNodes,
new Vertex());
}
public void bestFirstSearch(int adjacencyMatrix[][], int[] heuristicvalues,int source)
{
int evaluationNode;
int destinationNode;
int visited[] = new int [numberOfNodes + 1];
this.heuristicvalues = heuristicvalues;
priorityQueue.add(new Vertex(source, this.heuristicvalues[source]));
visited[source] = 1;
while (!priorityQueue.isEmpty())
{
evaluationNode = getNodeWithMinimumHeuristicValue();
destinationNode = 1;
System.out.print(evaluationNode + "\t");
while (destinationNode <= numberOfNodes)
{
Vertex vertex = new Vertex(destinationNode,this.heuristicvalues[destinationNode]);
if ((adjacencyMatrix[evaluationNode][destinationNode] != MAX_VALUE
&& evaluationNode != destinationNode)&& visited[destinationNode] == 0)
{
priorityQueue.add(vertex);
visited[destinationNode] = 1;
}
destinationNode++;
}
}
}
private int getNodeWithMinimumHeuristicValue()
{
Vertex vertex = priorityQueue.remove();
return vertex.node;
}
public static void main(String… arg)
{
int adjacency_matrix[][];
int number_of_vertices;
int source = 0;
int heuristicvalues[];
Scanner scan = new Scanner(System.in);
try
{
System.out.println("Enter the number of vertices");
number_of_vertices = scan.nextInt();
adjacency_matrix = new int[number_of_vertices + 1][number_of_vertices + 1];
heuristicvalues = new int[number_of_vertices + 1];
System.out.println("Enter the Weighted Matrix for the graph");
for (int i = 1; i <= number_of_vertices; i++)
{
for (int j = 1; j <= number_of_vertices; j++)
{
adjacency_matrix[i][j] = scan.nextInt();
if (i == j)
{
adjacency_matrix[i][j] = 0;
continue;
}
if (adjacency_matrix[i][j] == 0)
{
adjacency_matrix[i][j] = MAX_VALUE;
}
}
}
for (int i = 1; i <= number_of_vertices; i++)
{
for (int j = 1; j <= number_of_vertices; j++)
{
if (adjacency_matrix[i][j] == 1 && adjacency_matrix[j][i] == 0)
{
adjacency_matrix[j][i] = 1;
}
}
}
System.out.println("Enter the heuristic values of the nodes");
for (int vertex = 1; vertex <= number_of_vertices; vertex++)
{
System.out.print(vertex + ".");
heuristicvalues[vertex] = scan.nextInt();
System.out.println();
}
System.out.println("Enter the source ");
source = scan.nextInt();
System.out.println("The graph is explored as follows");
BestFirstSearch bestFirstSearch = new BestFirstSearch(number_of_vertices);
bestFirstSearch.bestFirstSearch(adjacency_matrix, heuristicvalues,source);
} catch (InputMismatchException inputMismatch)
{
System.out.println("Wrong Input Format");
}
scan.close();
}
}
class Vertex implements Comparator<Vertex>
{
public int heuristicvalue;
public int node;
public Vertex(int node, int heuristicvalue)
{
this.heuristicvalue = heuristicvalue;
this.node = node;
}
public Vertex()
{
}
@Override
public int compare(Vertex vertex1, Vertex vertex2)
{
if (vertex1.heuristicvalue < vertex2.heuristicvalue)
return -1;
if (vertex1.heuristicvalue > vertex2.heuristicvalue)
return 1;
return 0;
}
@Override
public boolean equals(Object obj)
{
if (obj instanceof Vertex)
{
Vertex node = (Vertex) obj;
if (this.node == node.node)
{
return true;
}
}
return false;
}
}
[/code]
– Algoritma A* :
[code language=”css”]
// Astar.cpp
// http://en.wikipedia.org/wiki/A*
// Compiler: Dev-C++ 4.9.9.2
// FB – 201012256
#include <iostream>
#include <iomanip>
#include <queue>
#include <string>
#include <math.h>
#include <ctime>
using namespace std;
const int n=60; // horizontal size of the map
const int m=60; // vertical size size of the map
static int map[n][m];
static int closed_nodes_map[n][m]; // map of closed (tried-out) nodes
static int open_nodes_map[n][m]; // map of open (not-yet-tried) nodes
static int dir_map[n][m]; // map of directions
const int dir=8; // number of possible directions to go at any position
// if dir==4
//static int dx[dir]={1, 0, -1, 0};
//static int dy[dir]={0, 1, 0, -1};
// if dir==8
static int dx[dir]={1, 1, 0, -1, -1, -1, 0, 1};
static int dy[dir]={0, 1, 1, 1, 0, -1, -1, -1};
class node
{
// current position
int xPos;
int yPos;
// total distance already travelled to reach the node
int level;
// priority=level+remaining distance estimate
int priority; // smaller: higher priority
public:
node(int xp, int yp, int d, int p)
{xPos=xp; yPos=yp; level=d; priority=p;}
int getxPos() const {return xPos;}
int getyPos() const {return yPos;}
int getLevel() const {return level;}
int getPriority() const {return priority;}
void updatePriority(const int & xDest, const int & yDest)
{
priority=level+estimate(xDest, yDest)*10; //A*
}
// give better priority to going strait instead of diagonally
void nextLevel(const int & i) // i: direction
{
level+=(dir==8?(i%2==0?10:14):10);
}
// Estimation function for the remaining distance to the goal.
const int & estimate(const int & xDest, const int & yDest) const
{
static int xd, yd, d;
xd=xDest-xPos;
yd=yDest-yPos;
// Euclidian Distance
d=static_cast<int>(sqrt(xd*xd+yd*yd));
// Manhattan distance
//d=abs(xd)+abs(yd);
// Chebyshev distance
//d=max(abs(xd), abs(yd));
return(d);
}
};
// Determine priority (in the priority queue)
bool operator<(const node & a, const node & b)
{
return a.getPriority() > b.getPriority();
}
// A-star algorithm.
// The route returned is a string of direction digits.
string pathFind( const int & xStart, const int & yStart,
const int & xFinish, const int & yFinish )
{
static priority_queue<node> pq[2]; // list of open (not-yet-tried) nodes
static int pqi; // pq index
static node* n0;
static node* m0;
static int i, j, x, y, xdx, ydy;
static char c;
pqi=0;
// reset the node maps
for(y=0;y<m;y++)
{
for(x=0;x<n;x++)
{
closed_nodes_map[x][y]=0;
open_nodes_map[x][y]=0;
}
}
// create the start node and push into list of open nodes
n0=new node(xStart, yStart, 0, 0);
n0->updatePriority(xFinish, yFinish);
pq[pqi].push(*n0);
open_nodes_map[x][y]=n0->getPriority(); // mark it on the open nodes map
// A* search
while(!pq[pqi].empty())
{
// get the current node w/ the highest priority
// from the list of open nodes
n0=new node( pq[pqi].top().getxPos(), pq[pqi].top().getyPos(),
pq[pqi].top().getLevel(), pq[pqi].top().getPriority());
x=n0->getxPos(); y=n0->getyPos();
pq[pqi].pop(); // remove the node from the open list
open_nodes_map[x][y]=0;
// mark it on the closed nodes map
closed_nodes_map[x][y]=1;
// quit searching when the goal state is reached
//if((*n0).estimate(xFinish, yFinish) == 0)
if(x==xFinish && y==yFinish)
{
// generate the path from finish to start
// by following the directions
string path="";
while(!(x==xStart && y==yStart))
{
j=dir_map[x][y];
c=’0’+(j+dir/2)%dir;
path=c+path;
x+=dx[j];
y+=dy[j];
}
// garbage collection
delete n0;
// empty the leftover nodes
while(!pq[pqi].empty()) pq[pqi].pop();
return path;
}
// generate moves (child nodes) in all possible directions
for(i=0;i<dir;i++)
{
xdx=x+dx[i]; ydy=y+dy[i];
if(!(xdx<0 || xdx>n-1 || ydy<0 || ydy>m-1 || map[xdx][ydy]==1
|| closed_nodes_map[xdx][ydy]==1))
{
// generate a child node
m0=new node( xdx, ydy, n0->getLevel(),
n0->getPriority());
m0->nextLevel(i);
m0->updatePriority(xFinish, yFinish);
// if it is not in the open list then add into that
if(open_nodes_map[xdx][ydy]==0)
{
open_nodes_map[xdx][ydy]=m0->getPriority();
pq[pqi].push(*m0);
// mark its parent node direction
dir_map[xdx][ydy]=(i+dir/2)%dir;
}
else if(open_nodes_map[xdx][ydy]>m0->getPriority())
{
// update the priority info
open_nodes_map[xdx][ydy]=m0->getPriority();
// update the parent direction info
dir_map[xdx][ydy]=(i+dir/2)%dir;
// replace the node
// by emptying one pq to the other one
// except the node to be replaced will be ignored
// and the new node will be pushed in instead
while(!(pq[pqi].top().getxPos()==xdx &&
pq[pqi].top().getyPos()==ydy))
{
pq[1-pqi].push(pq[pqi].top());
pq[pqi].pop();
}
pq[pqi].pop(); // remove the wanted node
// empty the larger size pq to the smaller one
if(pq[pqi].size()>pq[1-pqi].size()) pqi=1-pqi;
while(!pq[pqi].empty())
{
pq[1-pqi].push(pq[pqi].top());
pq[pqi].pop();
}
pqi=1-pqi;
pq[pqi].push(*m0); // add the better node instead
}
else delete m0; // garbage collection
}
}
delete n0; // garbage collection
}
return ""; // no route found
}
int main()
{
srand(time(NULL));
// create empty map
for(int y=0;y<m;y++)
{
for(int x=0;x<n;x++) map[x][y]=0;
}
// fillout the map matrix with a ‘+’ pattern
for(int x=n/8;x<n*7/8;x++)
{
map[x][m/2]=1;
}
for(int y=m/8;y<m*7/8;y++)
{
map[n/2][y]=1;
}
// randomly select start and finish locations
int xA, yA, xB, yB;
switch(rand()%8)
{
case 0: xA=0;yA=0;xB=n-1;yB=m-1; break;
case 1: xA=0;yA=m-1;xB=n-1;yB=0; break;
case 2: xA=n/2-1;yA=m/2-1;xB=n/2+1;yB=m/2+1; break;
case 3: xA=n/2-1;yA=m/2+1;xB=n/2+1;yB=m/2-1; break;
case 4: xA=n/2-1;yA=0;xB=n/2+1;yB=m-1; break;
case 5: xA=n/2+1;yA=m-1;xB=n/2-1;yB=0; break;
case 6: xA=0;yA=m/2-1;xB=n-1;yB=m/2+1; break;
case 7: xA=n-1;yA=m/2+1;xB=0;yB=m/2-1; break;
}
cout<<"Map Size (X,Y): "<<n<<","<<m<<endl;
cout<<"Start: "<<xA<<","<<yA<<endl;
cout<<"Finish: "<<xB<<","<<yB<<endl;
// get the route
clock_t start = clock();
string route=pathFind(xA, yA, xB, yB);
if(route=="") cout<<"An empty route generated!"<<endl;
clock_t end = clock();
double time_elapsed = double(end – start);
cout<<"Time to calculate the route (ms): "<<time_elapsed<<endl;
cout<<"Route:"<<endl;
cout<<route<<endl<<endl;
// follow the route on the map and display it
if(route.length()>0)
{
int j; char c;
int x=xA;
int y=yA;
map[x][y]=2;
for(int i=0;i<route.length();i++)
{
c =route.at(i);
j=atoi(&c);
x=x+dx[j];
y=y+dy[j];
map[x][y]=3;
}
map[x][y]=4;
// display the map with the route
for(int y=0;y<m;y++)
{
for(int x=0;x<n;x++)
if(map[x][y]==0)
cout<<".";
else if(map[x][y]==1)
cout<<"O"; //obstacle
else if(map[x][y]==2)
cout<<"S"; //start
else if(map[x][y]==3)
cout<<"R"; //route
else if(map[x][y]==4)
cout<<"F"; //finish
cout<<endl;
}
}
getchar(); // wait for a (Enter) keypress
return(0);
}
[/code]
Hello world!
012 years
by hiddenarmy
in Uncategorized
Welcome to Binusian blog.
This is the first post of any blog.binusian.org member blog. Edit or delete it, then start blogging!
Happy Blogging 🙂
Recent Comments